É um estrutura de dados probabilística, baseada em listas ligadas paralelas, cuja eficiência pode ser comparada à de uma árvore binária.
Fonte: Link

Uma skip list possui diversas camadas, onde a camada mais inferior é uma lista encadeada. Enquanto que a camada mais alta atua como uma forma de acesso para as listas abaixo.
Uma de suas propriedades é armazenar os dados de maneira ordenada.
- Altura máxima: é a maior altura que um nó pode possuir.
- Altura: a altura da skip list é a altura do maior nó, que não é nem o nó cabeça, nem o nó vazio.
- Probabilidade: é o valor usado no algoritmo para determinar aleatoriamente o nível (altura) de cada nó.
O método segue, basicamente, o passo a passo:
- Comece atravessando os apontadores que não levam a um elemento menor que o procurado.
- Depois siga para o elemento menor e aplique o mesmo raciocínio até descer ao nível 1.
- Depois é só seguir o próximo apontador do nivel 1 do ultimo nó visitado.
Fonte: GeeksforGeeks

Necessita de uma função randômica para definir o tamanho de um nó. E o passo a passo é bastante próximo ao da busca.
É importante salientar que é necessário armazenar os nós que irão mudar os apontadores assim que ocorrer a inserção do novo nó.
Fonte: Wikipedia

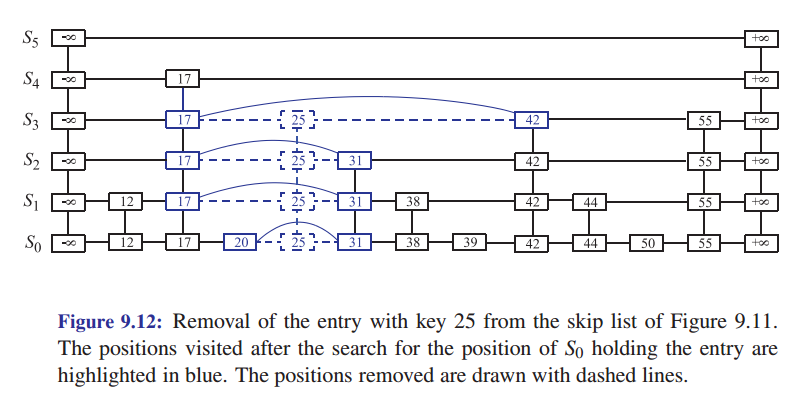
Para realizar a remoção é necessário procurar pelo nó e guardar os nós que necessitarão de atualização nos apontadores após a remoção do nó.
Fonte: Link
É a maior altura possível dos elementos, excluindo-se o HEADER e o NIL.
Lembrando que o último nível de uma skip list possui referências para todos os elementos da lista, então a ideia básica é percorrer o nível mais baixo da lista e ir inserindo no array e por fim é só retornar o produto final dessa iteração.
Para a implementação desse método deve-se utilizar a mesma ideia do toArray (percorrendo o último nível da lista).