| title | shortTitle | category | tag | description | head | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
一次生产环境中 CPU 占用 100% 排查优化实践 |
CPU 100%排查优化实战 |
|
|
本文介绍了一次生产环境中 CPU 占用 100% 排查优化实践。 |
|
前面给大家讲过一次 OOM 的优化排查实战,今天再给大家讲一个 CPU 100% 优化排查实战。
收到运维同学的报警,说某些服务器负载非常高,让我们开发定位问题。拿到问题后先去服务器上看了看,发现运行的只有我们的 Java 应用程序。于是先用 ps 命令拿到了应用的 PID。
ps:查看进程的命令;PID:进程 ID。
ps -ef | grep java可以查看所有的 Java 进程。前面也曾讲过。
接着使用 top -Hp pid 将这个进程的线程显示出来。输入大写 P 可以将线程按照 CPU 使用比例排序,于是得到以下结果。
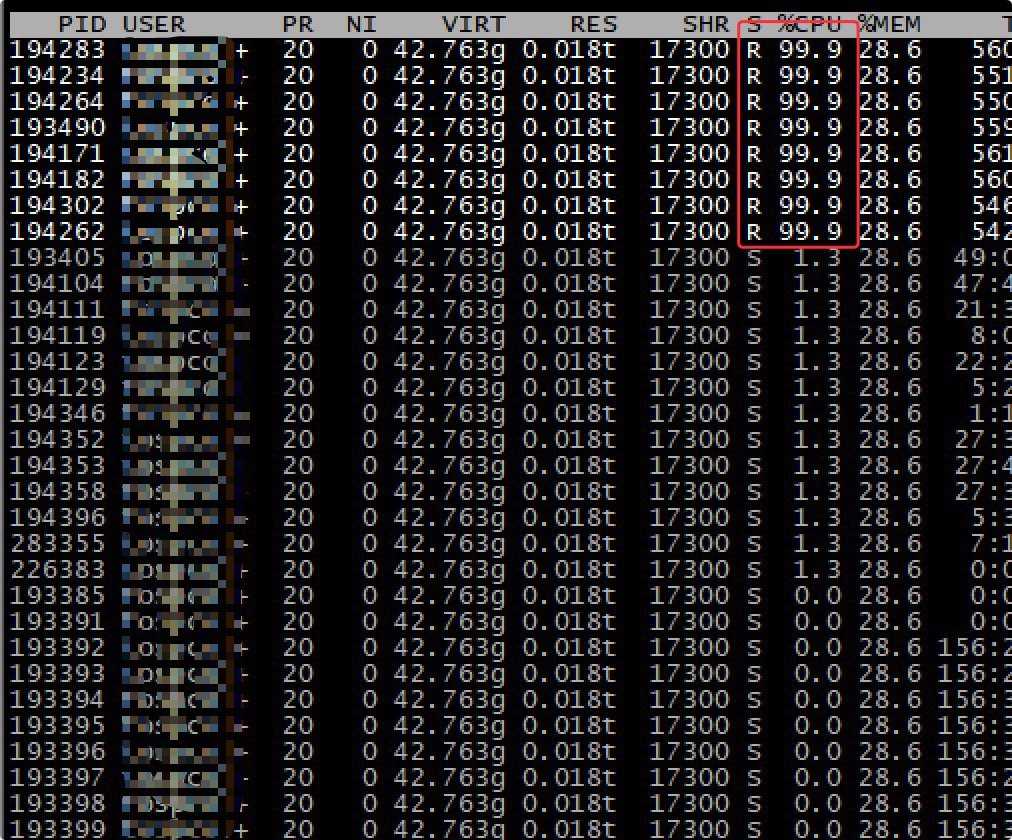
果然,某些线程的 CPU 使用率非常高,99.9% 可不是非常高嘛(😂)。
为了方便问题定位,我立马使用 jstack pid > pid.log 将线程栈 dump 到日志文件中。关于 jstack 命令,我们前面刚刚讲过。
我在上面 99.9% 的线程中随机选了一个 pid=194283 的,转换为 16 进制(2f6eb)后在线程快照中查询:

线程快照中线程 ID 都是16进制的。
发现这是 Disruptor 的一个堆栈,好家伙,这不前面刚遇到过嘛,老熟人啊, 强如 Disruptor 也发生内存溢出?
真没想到,再来一次!
为了更加直观的查看线程的状态,我将快照信息上传到了专门的分析平台上:http://fastthread.io/,估计有球友用过。
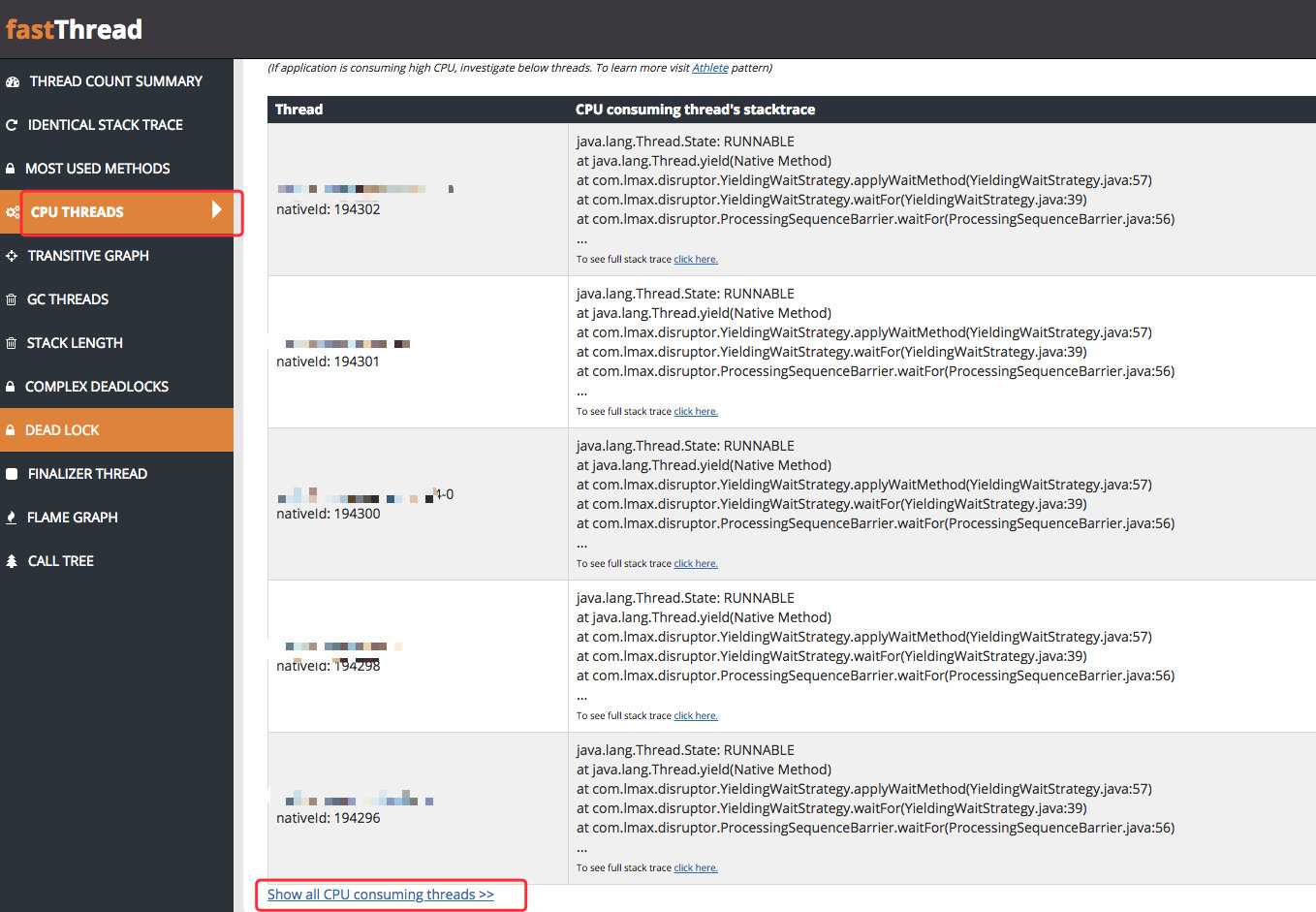
其中有一项展示了所有消耗 CPU 的线程,我仔细看了下,发现几乎都和上面的堆栈一样。
也就是说,都是 Disruptor 队列的堆栈,都在执行 java.lang.Thread.yield。
众所周知,yield 方法会暗示当前线程让出 CPU 资源,让其他线程来竞争(多线程的时候我们讲过 yield,相信大家还有印象)。
根据刚才的线程快照发现,处于 RUNNABLE 状态并且都在执行 yield 的线程大概有 30几个。
初步判断,大量线程执行 yield 之后,在互相竞争导致 CPU 使用率增高,通过对堆栈的分析可以发现,确实和 Disruptor 有关。
好家伙,又是它。
既然如此,我们来大致看一下 Disruptor 的使用方式吧。看有多少球友使用过。
第一步,在 pom.xml 文件中引入 Disruptor 的依赖:
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.4.2</version>
</dependency>第二步,定义事件 LongEvent:
public static class LongEvent {
private long value;
public void set(long value) {
this.value = value;
}
@Override
public String toString() {
return "LongEvent{value=" + value + '}';
}
}第三步,定义事件工厂:
// 定义事件工厂
public static class LongEventFactory implements EventFactory<LongEvent> {
@Override
public LongEvent newInstance() {
return new LongEvent();
}
}第四步,定义事件处理器:
// 定义事件处理器
public static class LongEventHandler implements EventHandler<LongEvent> {
@Override
public void onEvent(LongEvent event, long sequence, boolean endOfBatch) {
System.out.println("Event: " + event);
}
}第五步,定义事件发布者:
public static void main(String[] args) throws InterruptedException {
// 指定 Ring Buffer 的大小
int bufferSize = 1024;
// 构建 Disruptor
Disruptor<LongEvent> disruptor = new Disruptor<>(
new LongEventFactory(),
bufferSize,
Executors.defaultThreadFactory());
// 连接事件处理器
disruptor.handleEventsWith(new LongEventHandler());
// 启动 Disruptor
disruptor.start();
// 获取 Ring Buffer
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
// 生产事件
ByteBuffer bb = ByteBuffer.allocate(8);
for (long l = 0; l < 100; l++) {
bb.putLong(0, l);
ringBuffer.publishEvent((event, sequence, buffer) -> event.set(buffer.getLong(0)), bb);
Thread.sleep(1000);
}
// 关闭 Disruptor
disruptor.shutdown();
}简单解释下:
- LongEvent:这是要通过 Disruptor 传递的数据或事件。
- LongEventFactory:用于创建事件对象的工厂类。
- LongEventHandler:事件处理器,定义了如何处理事件。
- Disruptor 构建:创建了一个 Disruptor 实例,指定了事件工厂、缓冲区大小和线程工厂。
- 事件发布:示例中演示了如何发布事件到 Ring Buffer。
大家可以运行看一下输出结果。
我查了下代码,发现每一个业务场景在内部都会使用 2 个 Disruptor 队列来解耦。
假设现在有 7 个业务,那就等于创建了 2*7=14 个 Disruptor 队列,同时每个队列有一个消费者,也就是总共有 14 个消费者(生产环境更多)。
同时发现配置的消费等待策略为 YieldingWaitStrategy,这种等待策略会执行 yield 来让出 CPU。代码如下:
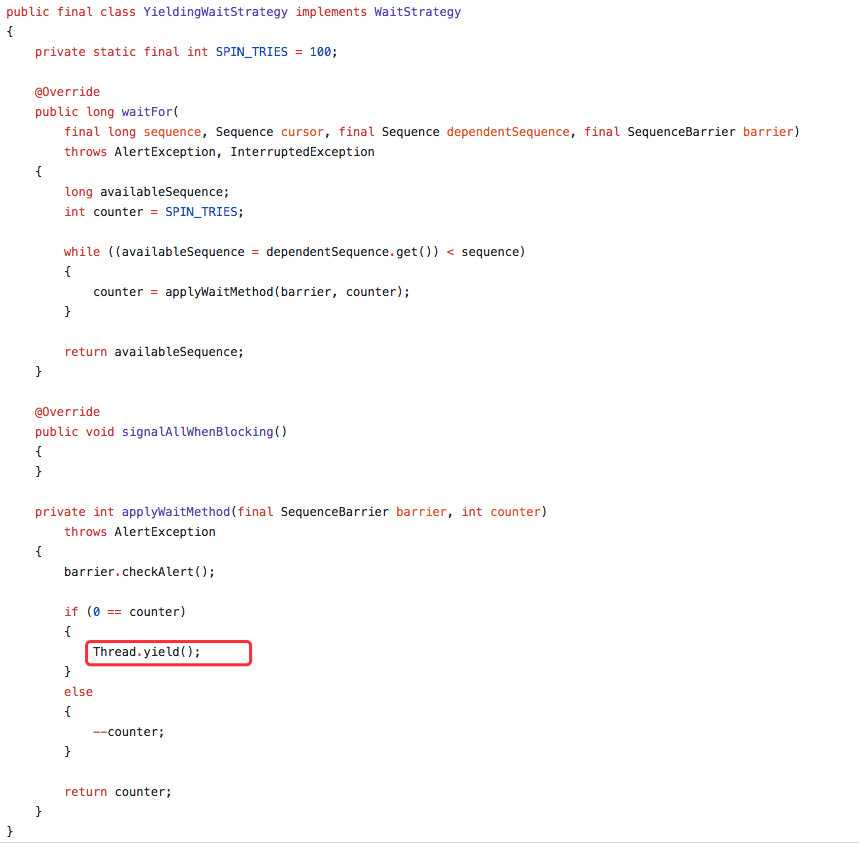
初步来看,和等待策略有很大的关系。
为了验证,我在本地创建了 15 个 Disruptor 队列,同时结合监控观察 CPU 的使用情况。
注意看代码 YieldingWaitStrategy:

以及事件处理器:

创建了 15 个 Disruptor 队列,同时每个队列都用线程池来往 Disruptor队列 里面发送 100W 条数据。消费程序仅仅只是打印一下。
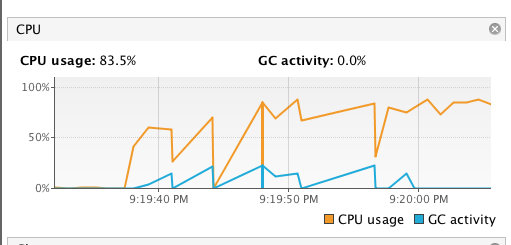
跑了一段时间,发现 CPU 使用率确实很高。
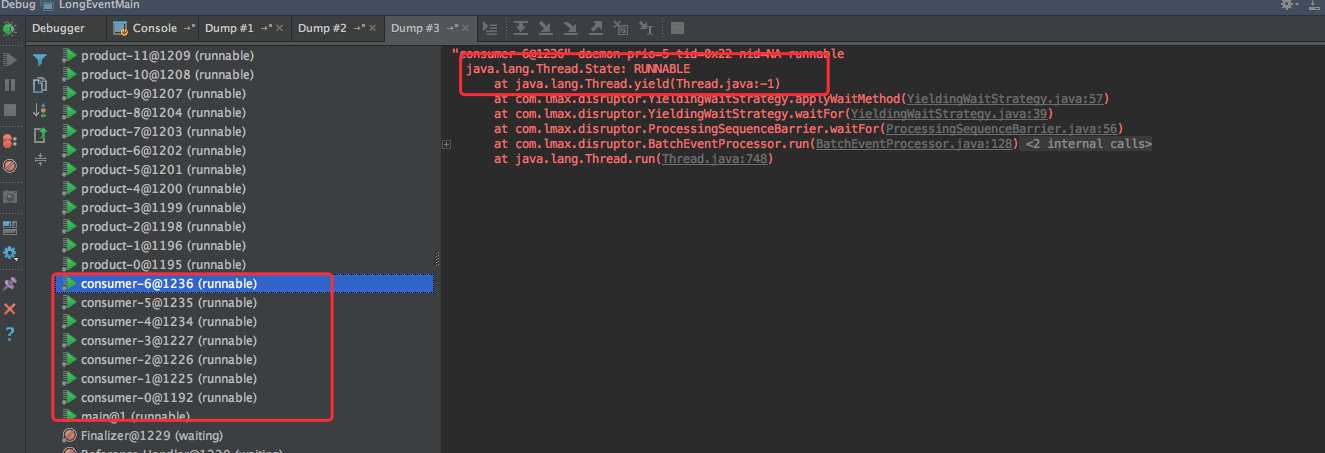
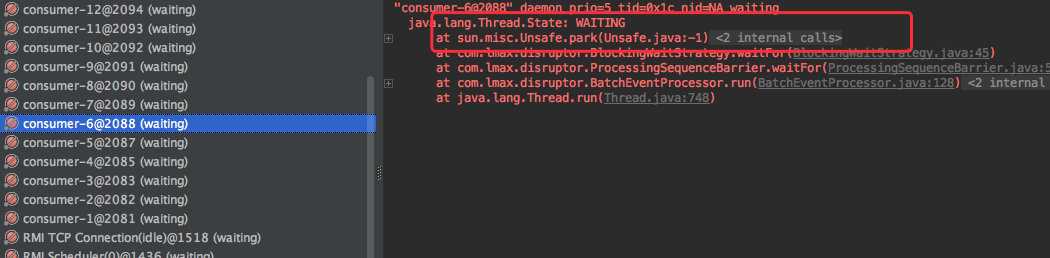
同时 dump 线程发现和生产环境中的现象也是一致的:消费线程都处于 RUNNABLE 状态,同时都在执行 yield。
通过查询 Disruptor 官方文档发现:

YieldingWaitStrategy 是一种充分压榨 CPU 的策略,使用自旋 + yield的方式来提高性能。当消费线程(Event Handler threads)的数量小于 CPU 核心数时推荐使用该策略。
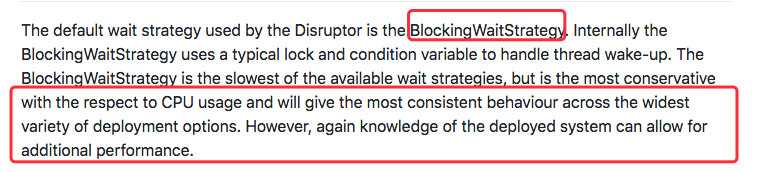
同时查到其他的等待策略,比如说 BlockingWaitStrategy (也是默认的策略),使用的是锁的机制,对 CPU 的使用率不高。
于是我将等待策略调整为 BlockingWaitStrategy。
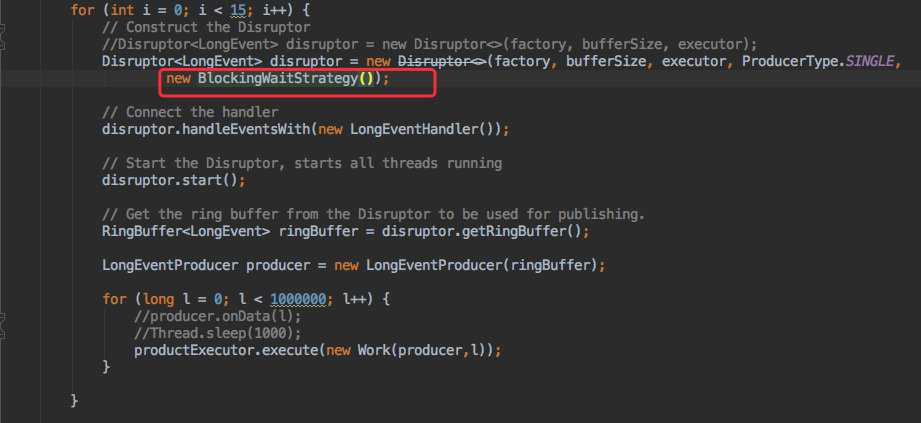
运行后的结果如下:
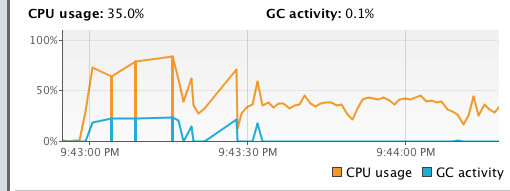
和刚才的结果对比,发现 CPU 的使用率有明显的降低;同时 dump 线程后,发现大部分线程都处于 waiting 状态。
看样子,将等待策略换为 BlockingWaitStrategy 可以减缓 CPU 的使用,不过我留意到官方对 YieldingWaitStrategy 的描述是这样的:
当消费线程(Event Handler threads)的数量小于 CPU 核心数时推荐使用该策略。
而现在的使用场景是,消费线程数已经大大的超过了核心 CPU 数,因为我的使用方式是一个 Disruptor 队列一个消费者,所以我将队列调整为 1 个又试了试(策略依然是 YieldingWaitStrategy)。
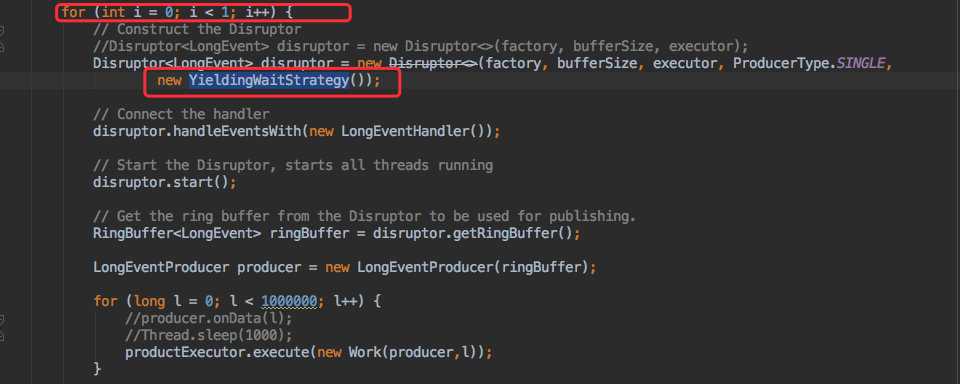
查看运行效果:
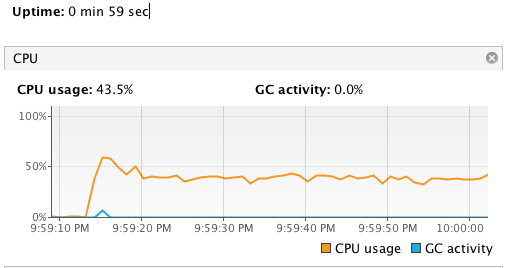
跑了一分钟,发现 CPU 的使用率一直都比较平稳。
排查到此,可以得出结论了,想要根本解决这个问题需要将我们现有的业务拆分;现在是一个应用里同时处理了 N 个业务,每个业务都会使用好几个 Disruptor 队列。
由于在一台服务器上运行,所以就会导致 CPU 的使用率居高不下。
由于是老系统,所以我们的调整方式如下:
- 先将等待策略调整为
BlockingWaitStrategy,可以有效降低 CPU 的使用率(业务上也还能接受)。 - 第二步就需要将应用拆分,一个应用处理一种业务类型;然后分别部署,这样可以互相隔离互不影响。
当然还有一些其他的优化,比如说这次 dump 发现应用程序创建了 800+ 个线程。创建线程池的方式也是核心线程数和最大线程数一样,就导致一些空闲的线程得不到回收。应该将创建线程池的方式调整一下,将线程数降下来,尽量物尽其用。
好,生产环境中,一般也就是会遇到 OOM 和 CPU 这两个问题,那也希望这种排查思路能够给大家一些启发~
- 演示代码已上传至 GitHub:https://github.com/crossoverJie/JCSprout
- 参考链接:crossoverJie 的CPU 100% 排查
GitHub 上标星 10000+ 的开源知识库《二哥的 Java 进阶之路》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:太赞了,GitHub 上标星 10000+ 的 Java 教程
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。
